1. 중심 경향성
- '중심 경향성'은 데이터의 중심이 어디 있는지를 나타내는 지표이다
- 평소에 우리가 자주 사용하는 평균도 중심 경향성을 나타내는 지표 중 하나이다
- 중심 경향성을 알면 분포의 중앙을 알 수 있어 데이터의 특성을 파악하기 쉬워진다
- 평균, 중앙값, 최빈값 등이 있다
2. 평균(mean)
- 평균은 전체 주어진 자료의 값을 모두 더한 후 자료의 개수로 나눈 값이다
- N개의 자료가 주어질 때 임의 하나의 값이 1증가시켜도 전체 평균은 1/N만큼 증가한다
- 데이터가 바뀌어도 값의 변화가 급격하지 않다
- 이상치(특이값)에 민감하다(튀는 값이 하나 있으면 평균이 크게 바뀌어 버린다)
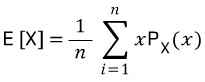

3. 중앙값(median)
- 중앙값은 전체 데이터의 정중앙에 있는 값을 의미한다
- 데이터의 개수가 짝수라면 중앙값은 중앙의 두 데이터의 평균이 된다
- 정중앙값에만 관심이 있으므로 평균에 비해 이상치에 민감하지 않다
4. 최빈값(mode)
- 최빈값은 전체 데이터에서 가장 자주 나오는 값을 의미한다
- 평균이나 중앙값에 비해 사용되는 빈도가 적다
5. 프로그래밍
(1) 평균
def mean(xs):
return sum(xs)/len(xs)- 리스트 xs를 받을 경우 xs의 합을 구한 후 xs의 크기로 나누어 준다
(2) 중앙값
def median(xs):
sorted_xs = sorted(xs)
if len(sorted_xs)%2 == 0:
mid_point=len(sorted_xs)//2
return (sorted_xs[mid_point]+sorted_xs[mid_point-1])/2
else:
mid_point=len(sorted_xs)//2
return sorted_xs[mid_point]- 리스트의 길이가 짝수일 때는 중앙의 두 값의 평균을 반환한다
- 리스트의 길이가 홀수일 때는 중앙의 값을 반환한다
- 리스트의 인덱스는 0부터 시작한다
(3) 최빈값
- 최빈값을 구하기 위해 리스트의 원소의 빈도를 구해야 한다
- collections의 Counter 함수를 사용하면 쉽게 구할 수 있다
from collections import Counter
import random
list=[]
for i in range(100):
list.append(random.randrange(10))
print(Counter(list))
다시 최빈값 계산으로 돌아오면,
def mode(xs):
counts = Counter(xs)
max_count = max(counts.values())
return [[x_i, count] for x_i, count in counts.items()
if count == max_count]- 이 때, 최빈값이 여러 개 존재할 수 있으므로, 리스트로 반환한다
- 최빈값과 최빈값의 빈도를 리스트로 묶어 반환한다
(4) 랜덤한 수가 주어질 때, 중심 경향성 구하기
from collections import Counter
import random
list=[]
for i in range(1000):
list.append(random.randrange(11))
print(mean(list), median(list), mode(list))
'DataScience' 카테고리의 다른 글
| 이항분포의 정의와 평균, 분산 (0) | 2020.08.02 |
|---|---|
| 베르누이분포의 정의와 평균, 분산 (0) | 2020.08.02 |
| [Numpy] 개요 (0) | 2020.08.02 |
| 산포도 (사분위수, 범위, 분산, 표준편차) (0) | 2020.07.22 |
| 기하분포의 정의와 평균 (0) | 2020.04.24 |