[Pandas] 빈도표 구하기, 카이제곱검정(crosstab, chi2_contingency)
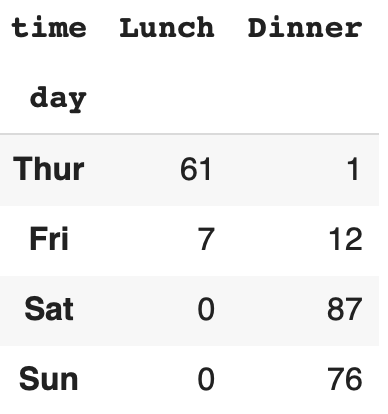
1. pandas.crosstab crosstab은 범주형 변수를 기준으로 데이터의 개수를 파악할 때 사용합니다. crosstab을 사용해 빈도표를 만들어 카이제곱검정을 할 때도 유용합니다. 파라미터 설명 index: array-like, Series,list, arrays 행으로 지정할 데이터 columns: array-like, Series, list, arrays 열로 지정할 데이터 values: array-like, optional 집계할 데이터 (aggfunc을 같이 사용해야 합니다) aggfunc: function, optional 집계할 방법을 선택(count, mean, median ...) margins: bool, default=False 총계를 보고 싶은 경우 사용 dropna: bo..