scipy.stats에서 제공하는 ttest_ind를 사용하면 t검정을 수행할 수 있습니다.
하지만 ttest_ind는 입력값으로 array_like를 받기 때문에 원본 데이터값이 있을 때만 사용할 수 있습니다.
데이터가 없고 데이터에 대한 통계량만 있는 경우 t검정과 z검정을 수행하는 방법에 대해 정리해보겠습니다.
1. t검정(t-test)
| 파라미터 | 설명 |
| x_bar | 표본평균 float |
| mu | 검저하고자 하는 평균값 float |
| s | 표본표준편차 float |
| n | 표본크기 int |
| alpha | 신뢰수준 float default=0.05 |
| two_sided | 양측검정 여부 bool defalut=True |
t검정을 하기 위해서는 먼저 검정통계량인 t0를 구해야 합니다.

t_value = (x_bar - mu) * sqrt(n) / s검정통계량값과 t분포표를 이용해 가설검정을 할 수도 있는데 여기서는 누적분포표와 p-value를 이용해 가설검정을 해보겠습니다.
scipy.stats.t.sf를 사용하면 t분포의 생존함수(1 - 누적함수)를 구할 수 있습니다.(즉, 오른쪽 꼬리 영역을 구할 수 있습니다)
이를 이용해 t검정을 하는 함수를 만들어보겠습니다.
from scipy.stats import t
from typing import Tuple
from math import sqrt
def t_test(x_bar: float, mu: float, s: float,
n: int, alpha: float=0.05,
two_sided: bool=True) -> Tuple[float, float, str]:
t_value = (x_bar - mu) * sqrt(n) / s
if two_sided:
p_value = t.sf(abs(t_value), n - 1) * 2
else:
p_value = t.sf(abs(t_value), n - 1)
return (t_value, p_value, "H0 채택" if p_value > alpha else "H0 기각")
양측검정의 경우에는 p-value가 한 쪽 꼬리의 2배만큼이므로 P-value를 2배 곱해줍니다.
반면 단측검정의 경우 검정통계량 값의 절대값을 사용하기 때문에 오른쪽 꼬리와 왼쪽 꼬리를 구분하지 않고 풀었습니다.
2. z검정(z-test)
| 파라미터 | 설명 |
| x_bar | 표본평균 float |
| mu | 검정하고자 하는 평균 float |
| sigma | 모표준편차 float |
| n | 표본크기 float |
| alpha | 신뢰수준 float default=0.05 |
| two_sided | 양측검정여부 bool default=True |

z검정도 t검정과 거의 유사하게 진행됩니다. 여기서는 모표준편차를 알고 있기 때문에 표본표준편차가 아닌 모표준편차를 이용해 검정통계량을 구합니다. 또 정규분포의 생존함수(1 - 누적함수)를 사용해 p-value를 구할 수 있습니다.
from scipy.stats import norm
from typing import Tuple
from math import sqrt
def z_test(x_bar: float, mu: float, sigma: float,
n: int, alpha: float=0.05,
two_sided: bool=True) -> Tuple[float, float, str]:
z_value = (x_bar - mu) * sqrt(n) / sigma
if two_sided:
p_value = norm.sf(abs(z_value)) * 2
else:
p_value = norm.sf(abs(z_value))
return (z_value, p_value, "H0 채택" if alpha < p_value else "H0 기각")
3. 예제
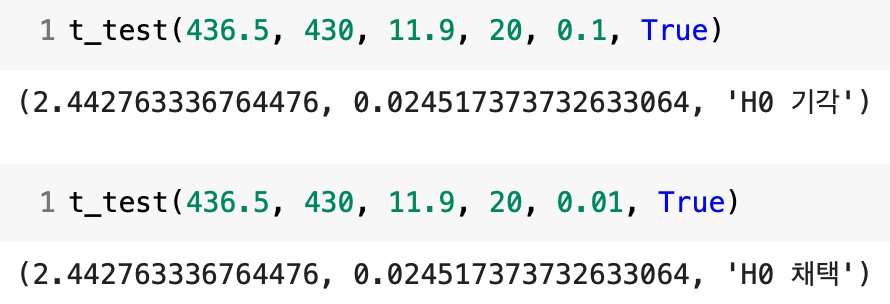
1) t검정


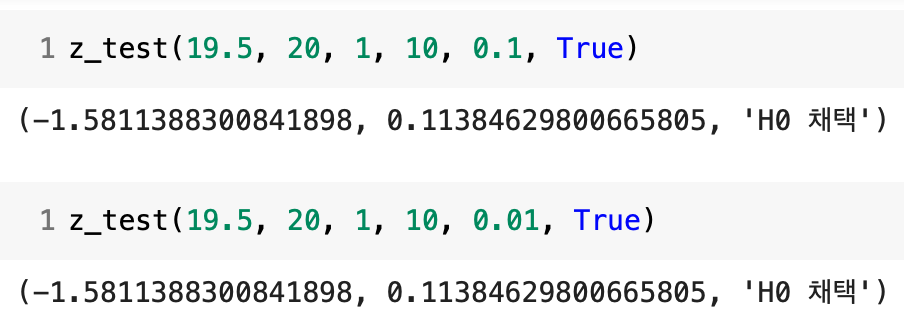
2) z검정


여기서는 모집단의 표준편차를 알고 있기 때문에 t검정이 아닌 z검정을 사용해 가설검정을 할 수 있다.
t검정과 z검정에 대해서 간단히 알아보았습니다.
'DataScience' 카테고리의 다른 글
| [Python] 두 표본에 대한 모평균 검정 (0) | 2022.10.05 |
|---|---|
| [Python] t분포의 신뢰구간(Confidence Interval, CI) (0) | 2022.10.05 |
| [ML] 분류모형의 평가지표(confusion matrix, accuracy, precision, sensitivity(recall), specificity, F1-score) (0) | 2022.09.02 |
| [ML] MAB(Multi-Armed Bandit Algorithm, 멀티 암드 밴딧) (0) | 2022.09.02 |
| [Pandas] UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbb in position 2: invalid start byte (0) | 2022.08.23 |