
Koo's.Co
[ML] K-NeighborsClassifier(K-최근접 이웃) 본문
도미의 길이, 무게 데이터
도미의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
빙어의 길이, 무게 데이터
빙어의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
위 데이터를 이용해 K-최근접 이웃 모델에 대해 공부해보겠습니다.
K-최근접 이웃 분류 모델은 지도학습 중에서도 분류 알고리즘에 해당하는 알고리즘입니다.
K-최근접 이웃 모델은 별도의 규칙을 찾기보다는 전체 데이터를 메모리에 저장하는 역할만 합니다.
새로운 데이터가 주어지면 기존에 있던 데이터들 중에서 새로운 데이터와 유클리디언 거리가 가장 가까운 이웃들을 구합니다. 확인해볼 이웃의 수(새로운 데이터와 가까운 근접 데이터들)는 사용자가 정할 수 있습니다!
1. 데이터 전처리
먼저 데이터를 확인해보겠습니다.
import matplotlib.pyplot as plt
bream_length = [25.4, 26.3, 26.5, 29.0, 29.0, 29.7, 29.7, 30.0, 30.0, 30.7, 31.0, 31.0,
31.5, 32.0, 32.0, 32.0, 33.0, 33.0, 33.5, 33.5, 34.0, 34.0, 34.5, 35.0,
35.0, 35.0, 35.0, 36.0, 36.0, 37.0, 38.5, 38.5, 39.5, 41.0, 41.0]
bream_weight = [242.0, 290.0, 340.0, 363.0, 430.0, 450.0, 500.0, 390.0, 450.0, 500.0, 475.0, 500.0,
500.0, 340.0, 600.0, 600.0, 700.0, 700.0, 610.0, 650.0, 575.0, 685.0, 620.0, 680.0,
700.0, 725.0, 720.0, 714.0, 850.0, 1000.0, 920.0, 955.0, 925.0, 975.0, 950.0]
smelt_length = [9.8, 10.5, 10.6, 11.0, 11.2, 11.3, 11.8, 11.8, 12.0, 12.2, 12.4, 13.0, 14.3, 15.0]
smelt_weight = [6.7, 7.5, 7.0, 9.7, 9.8, 8.7, 10.0, 9.9, 9.8, 12.2, 13.4, 12.2, 19.7, 19.9]
plt.scatter(bream_length, bream_weight, label='bream')
plt.scatter(smelt_length, smelt_weight, label='smelt')
plt.xlabel('length')
plt.ylabel('weight')
plt.legend()
plt.show()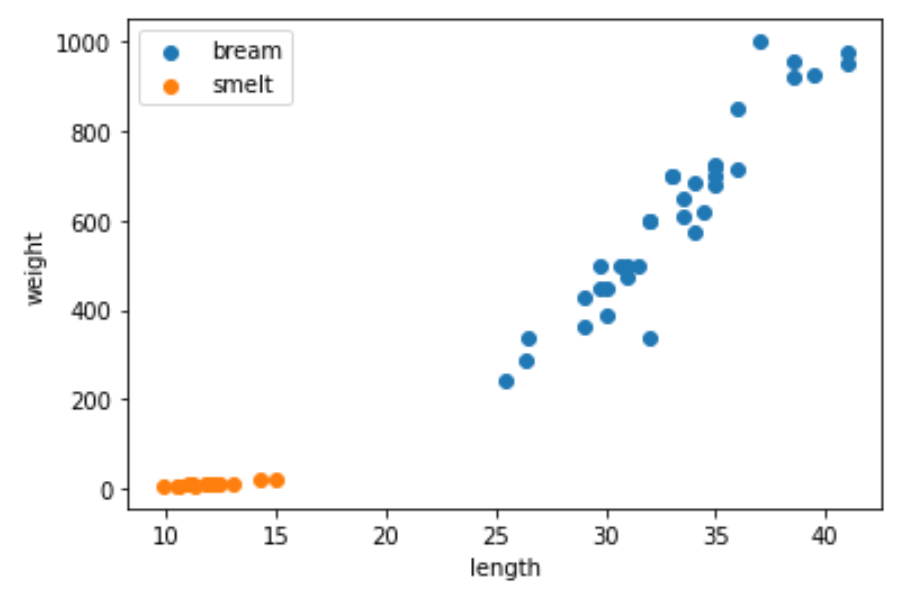
그래프를 통해 bream과 smelt에는 확실한 차이가 있음을 확인할 수 있습니다.
length와 weight 데이터를 합쳐서 길이-무게를 갖는 2-d ndarray를 생성하겠습니다.
또 bream은 1, smelt는 0으로 레이블링하여 target이 되는 데이터를 생성해주겠습니다.
import numpy as np
length = np.concatenate((bream_length, smelt_length))
weight = np.concatenate((bream_weight, smelt_weight))
fish_data = np.column_stack((length, weight))
fish_target = np.concatenate((np.ones(35), np.zeros(14)))
print(fish_data.shape) # (49, 2)
print(fish_target.shape) # (49, )다음으로 train_test_split을 이용해 학습용 데이터와 테스트용 데이터를 나누겠습니다.
train_test_split에서 stratify에 target 데이터를 주면 target의 비율에 맞춰서 훈련용 데이터와 테스트용 데이터를 나눠줍니다.
random seed는 9로 고정시켜주겠습니다.
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(fish_data, fish_target,
stratify=fish_target, random_state=9)
K-최근접 이웃 모델은 거리를 기반으로 이웃을 판단하기 때문에 학습하기 전에 데이터들의 정규화가 필요합니다.
무게와 길이 데이터는 서로 단위가 다르기 때문에 먼저 단위에 의한 영향을 없애기 위해 정규화를 해야 합니다.
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)StandardScaler는 변환기의 한 종류로, fit와 transform을 통해 데이터를 정규화시켜 줍니다.
fit을 사용해 학습용 데이터에 대해 학습하고 이에 맞춰 학습용 데이터와 테스트용 데이터를 정규화시킬 수 있습니다.
주의! 테스트용 데이터를 정규화할 때는 학습용 데이터를 이용해 정규화를 시켜야 합니다!
나눠진 학습용 데이터와 테스트용 데이터, 정규화된 내용을 그래프를 통해 확인하면 다음과 같습니다.
plt.scatter(train_scaled[:, 0], train_scaled[:, 1], label='train data')
plt.scatter(test_scaled[:, 0], test_scaled[:, 1], label='test data')
plt.xlabel('length')
plt.ylabel('weight')
plt.legend()
plt.show()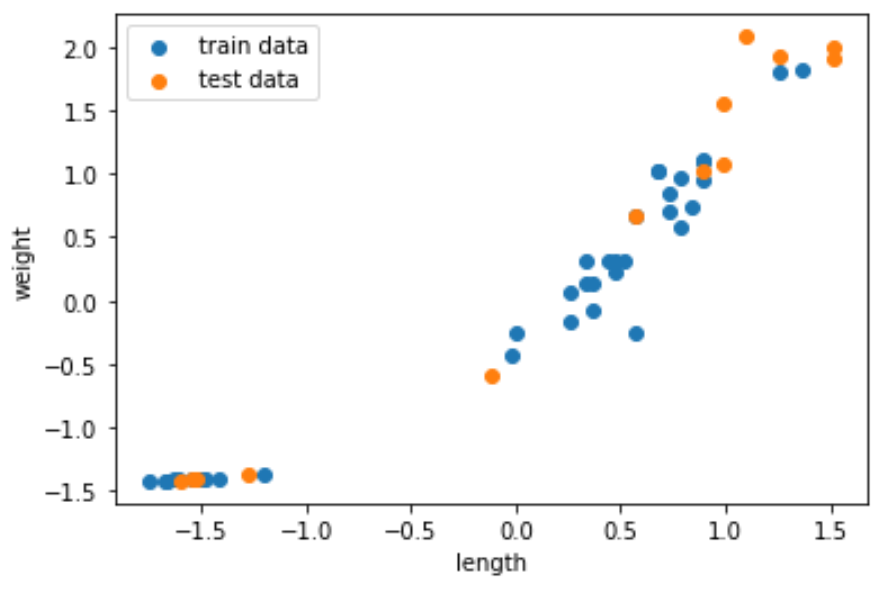
2. 모델 학습
드디어 데이터 전처리 과정이 끝나고 이제 모델을 학습시켜 보겠습니다.
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier()
kn.fit(train_scaled, train_target)
print(kn.score(train_sacled, train_target)) # 1.0
print(kn.score(test_sacled, test_target)) # 1.0sklearn에서 제공되는 모델들은 fit을 이용해 학습용 데이터를 학습하고, score를 이용해 테스트용 데이터가 들어왔을 때의 정확도를 판단합니다. 과대적합인지 과소적합인지 판단하기 위해 학습용 데이터와 테스트용 데이터의 정확도를 모두 구하고 둘의 값을 비교해야 합니다.
여기서는 데이터의 크기가 워낙 작고 극단적이기 때문에 모델의 성능이 1로 나왔는데 오늘은 K-최근접 이웃 모델의 사용법에 중점을 두었기 때문에 신경쓰지 않고 진행하겠습니다.
3. 새로운 데이터 예측
이제 새로운 데이터를 추가하고 결과를 확인해보겠습니다.
new = ss.transform([[25, 150]])
print(kn.predict(new) # array([1.]), 새로운 데이터를 bream으로 예측KNeighborsClassifier의 kneighbors를 사용하면 새로운 데이터와 가장 근접한 이웃들의 거리와 인덱스를 구할 수 있습니다.
dists, idxs = kn.kneighbors(new)
plt.scatter(kn._fit_X[:, 0], kn._fit_X[:, 1], c='black', label='train data')
plt.scatter(new[0, 0], new[0, 1], c='red', marker='x', label='new data')
plt.scatter(kn._fit_X[idxs, 0], kn._fit_X[idxs, 1], c='orange', marker='D', label='neighbors')
plt.xlabel('length')
plt.ylabel('weight')
plt.legend()
plt.show()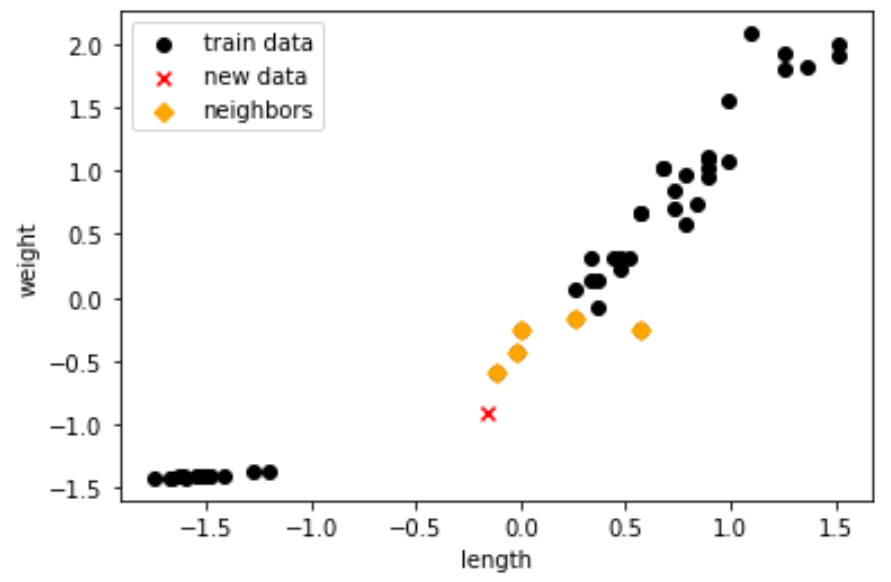
K-NeigborsClassifier은 연속형 데이터들을 이용해 범주형 데이터인 target의 값을 예측할 수 있도록 학습합니다.
fit 메서드를 통해 모델이 데이터를 학습하고 score 메서드를 통해 테스트용 데이터가 들어왔을 때의 정확도를 계산할 수 있습니다. 마지막으로 predict 메서드를 사용해 새로운 데이터가 들어왔을 때의 예측값을 얻을 수 있습니다.
참고서적
혼자 공부하는 머신러닝+딥러닝, 2020, 박해선
'DataScience' 카테고리의 다른 글
| [ML] SimpleImputer (누락값 처리) (0) | 2022.08.04 |
|---|---|
| [ML] 모델 파라미터와 모델 하이퍼 파라미터 차이 (Difference between a model parameter and a model hyper parameter) (0) | 2022.08.02 |
| [ML] 머신러닝 시스템의 종류 (0) | 2022.07.27 |
| [Numpy] Poly1d 그래프 plot (0) | 2022.07.14 |
| [Matplotlib] PieChart(파이차트) (0) | 2022.07.11 |


