[ML] K-NeighborsClassifier(K-최근접 이웃)
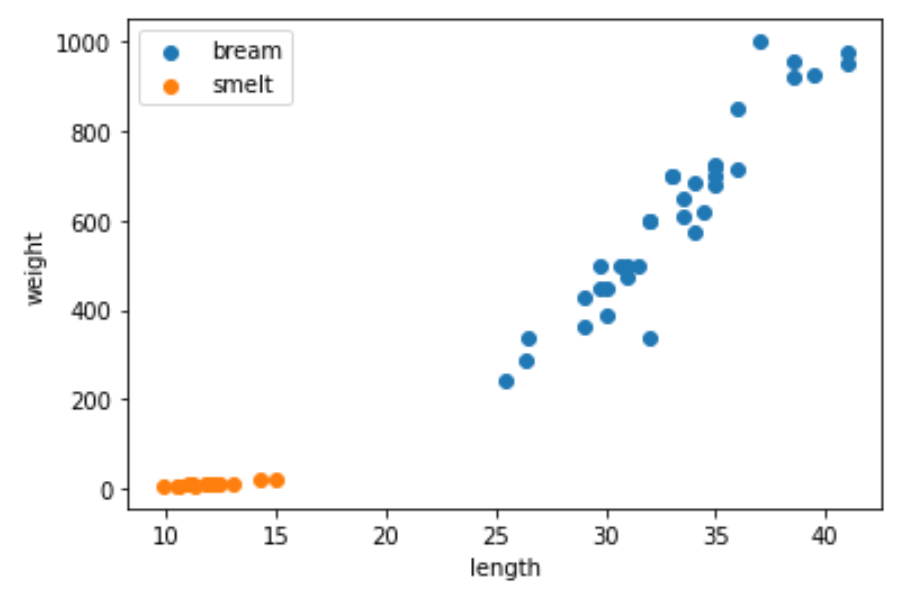
도미의 길이, 무게 데이터 도미의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets. gist.github.com 빙어의 길이, 무게 데이터 빙어의 길이, 무게 데이터. GitHub Gist: instantly share code, notes, and snippets. gist.github.com 위 데이터를 이용해 K-최근접 이웃 모델에 대해 공부해보겠습니다. K-최근접 이웃 분류 모델은 지도학습 중에서도 분류 알고리즘에 해당하는 알고리즘입니다. K-최근접 이웃 모델은 별도의 규칙을 찾기보다는 전체 데이터를 메모리에 저장하는 역할만 합니다. 새로운 데이터가 주어지면 기존에 있던 데이터들 중에서 새로운 데이터와 유클리디언 거리가 가장 ..