train_test_split을 사용하면 데이터셋을 train 데이터와 test 데이터로 분리할 수 있습니다.
하지만 train 데이터를 이용해 모델을 학습하고 test 데이터로 모델의 적합성 여부를 계속해서 판단하다 보면, 모델은 test데이터에 맞춰지게 됩니다.
그렇기 때문에 test 데이터는 마지막에 한 번만 사용해야 합니다. train 데이터를 다시 train 데이터와 검증용 데이터로 나누고, train 데이터로 학습한 후 검증용 데이터로 모델을 평가합니다.

교차 검증
train 데이터의 일부를 사용해 검증 세트를 만들었기 때문에 train 데이터가 많이 줄어들었습니다. 하지만 train 데이터를 늘리려고 검증 세트를 줄이게 되면 검증 점수가 불안정해집니다.
교차검증을 사용하면 안정적인 검증 점수를 얻고, 훈련에 더 많은 데이터를 사용할 수 있습니다.

교차검증은 검증 세트를 떼어 평가하는 과정을 반복합니다. 검증 횟수를 k라고 할 때, k-폴드 교차검증이라 합니다.
위 그림에서는 검증 횟수가 3번이기 때문에 3-폴드 교차검증입니다. 보통 5-폴드 교차검증, 10-폴드 교차검증을 많이 사용합니다.
sklearn.model_selection의 cross_validate를 사용하면 교차검증을 수행할 수 있습니다.
| 파라미터 | 설명 |
| estimator | 데이터를 학습할 모델 |
| X | input 데이터 |
| y | target 데이터 |
| cv | 훈련 세트를 섞기 위한 분할기 지정 |
| n_jobs | 연산을 위한 CPU 코어 개수 지정 -1인 경우 모든 코어를 사용 |
import seaborn as sns
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_validate, train_test_split
iris = sns.load_dataset('iris')
data = iris[iris.columns[:4]]
target = iris['species']
train_X, test_X, train_y, test_y = train_test_split(data, target)
scores = cross_validate(DecisionTreeClassifier(), train_X, train_y)
scores
DecisionTreeClassifier를 교차검증을 이용해 5-폴드 교차검증을 수행한 결과를 나타냅니다. cross_validate를 사용하면, 'fit_time', 'score_time', 'test_score'를 반환하고 'test_score'의 평균을 구하여 검증 점수 평균을 구할 수 있습니다.
import numpy as np
np.mean(scores['test_score'])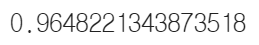
* 분할기의 지정
cross_validate는 train 데이터를 섞어 폴드를 나누지 않습니다. 교차 검증을 할 때 train 데이터를 섞으려면 분할기(splitter)를 지정해야 합니다.
- 회귀 모델: KFold
- 분류 모델: StratifiedKFold
분류 모델을 사용하는 경우, 층화를 통해 target 데이터가 골고루 표집될 수 있도록 StratifiedKFold 분할기를 사용합니다.
| 파라미터 | 설명 |
| n_splits | 폴드의 개수를 지정(default=5) |
| shuffle | 섞어서 폴드를 나눌지 지정(True/False) |
| random_state | seed값 설정 |
KFold와 StratifiedKFold 둘 모두 위의 파라미터를 사용합니다.
'DataScience' 카테고리의 다른 글
| 임의순열검정(random permutation test) (0) | 2022.08.23 |
|---|---|
| [ML] 회귀모형의 평가지표, MAE, MSE, RMSE, RSE, R^2 (0) | 2022.08.23 |
| [ML] train_test_split을 이용한 데이터 분할 (0) | 2022.08.22 |
| [ML] K-NeighborsRegressor (K-최근접 이웃 회귀) (0) | 2022.08.04 |
| [ML] SimpleImputer (누락값 처리) (0) | 2022.08.04 |