1. K-NeighborsRegressor(K-최근접 이웃 회귀 알고리즘)
K-최근접 이웃 모델은 분류 모델뿐만 아니라 회귀 모델도 만들 수 있습니다.
분류 모델에서는 범주형 데이터를 예측한다면, 회귀 모델에서는 연속형 데이터를 예측합니다.

분류 모델과 마찬가지로 train 데이터가 입력되면 데이터를 저장하고 있다가 새로운 값들이 들어오면 근접한 이웃들의 평균값을 계산해 예측값으로 반환합니다.
오늘은 농어의 길이와 무게 데이터를 이용해 K-최근접 이웃 회귀 모델을 공부해보겠습니다.
농어의 길이와 무게 데이터
농어의 길이와 무게 데이터. GitHub Gist: instantly share code, notes, and snippets.
gist.github.com
import numpy as np
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])우선 테스트 데이터를 나누기 전에 간단하게 데이터 산점도만 확인해보겠습니다.
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 12))
plt.scatter(perch_length, perch_weight, s=100)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
데이터를 보면 다항 회귀를 적용하면 좋을 것 같은데 오늘은 K-최근접 이웃을 사용해보겠습니다.
from sklearn.model_selection import train_test_split
perch_length = perch_length.reshape(-1, 1)
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight,
random_state=42)K-최근접 이웃 모델은 입력 데이터를 2차원 배열로 받기 때문에 먼저 입력 데이터를 2차원 배열로 만들고 테스트 데이터를 나눠주었습니다.
이미 가공돼 있는 데이터이고 예측값이 target의 평균으로 계산되기 때문에 정규화를 거치지 않고 바로 모델에 넣어보겠습니다.
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor(n_neighbors=3)
knr.fit(train_input, train_target)
print(knr.predict([[35]])) # 698.666667모델을 통해 구한 예측치를 확인해보겠습니다.
import matplotlib.pyplot as plt
dists, idxs = knr.kneighbors([[35]]) # 예측치 주위 이웃들의 거리와 인덱스를 반환
plt.figure(figsize=(16, 12))
plt.scatter(train_input, train_target, s=100, color='black')
plt.scatter(train_input[idxs], train_target[idxs], s=100, marker='D') # 입력값의 이웃들
plt.scatter(35, 698.6667, s=100, color='red', marker='^')
plt.xlabel('length', fontsize=20)
plt.ylabel('weight', fontsize=20)
plt.show()
2. 알고리즘의 문제점
모델을 통해 target을 정상적으로 예측하는 것을 확인했습니다. 하지만 K-최근접 이웃 모델에는 엄청난 문제점이 있습니다. 학습된 데이터는 별도의 처리 없이 모델에 저장되어 있는 상태입니다. 이웃들의 평균값을 계산해 예측값을 반환하는 부분이 문제입니다.
print(knr.predict([[50]])) # 1033.3333
print(knr.predict([[100]])) # 1033.3333?? 길이에 엄청난 차이가 있지만 둘 다 동일한 예측값을 반환받았습니다.
distances, indexes = knr.kneighbors([[100]])
plt.figure(figsize=(16, 12))
plt.scatter(train_input, train_target, s=100, color='black')
plt.scatter(train_input[indexes], train_target[indexes], marker='D', s=100)
plt.scatter(50, 1033, marker='^', s=100, color='red')
plt.xlabel('length', fontsize=20)
plt.ylabel('weight', fontsize=20)
plt.show()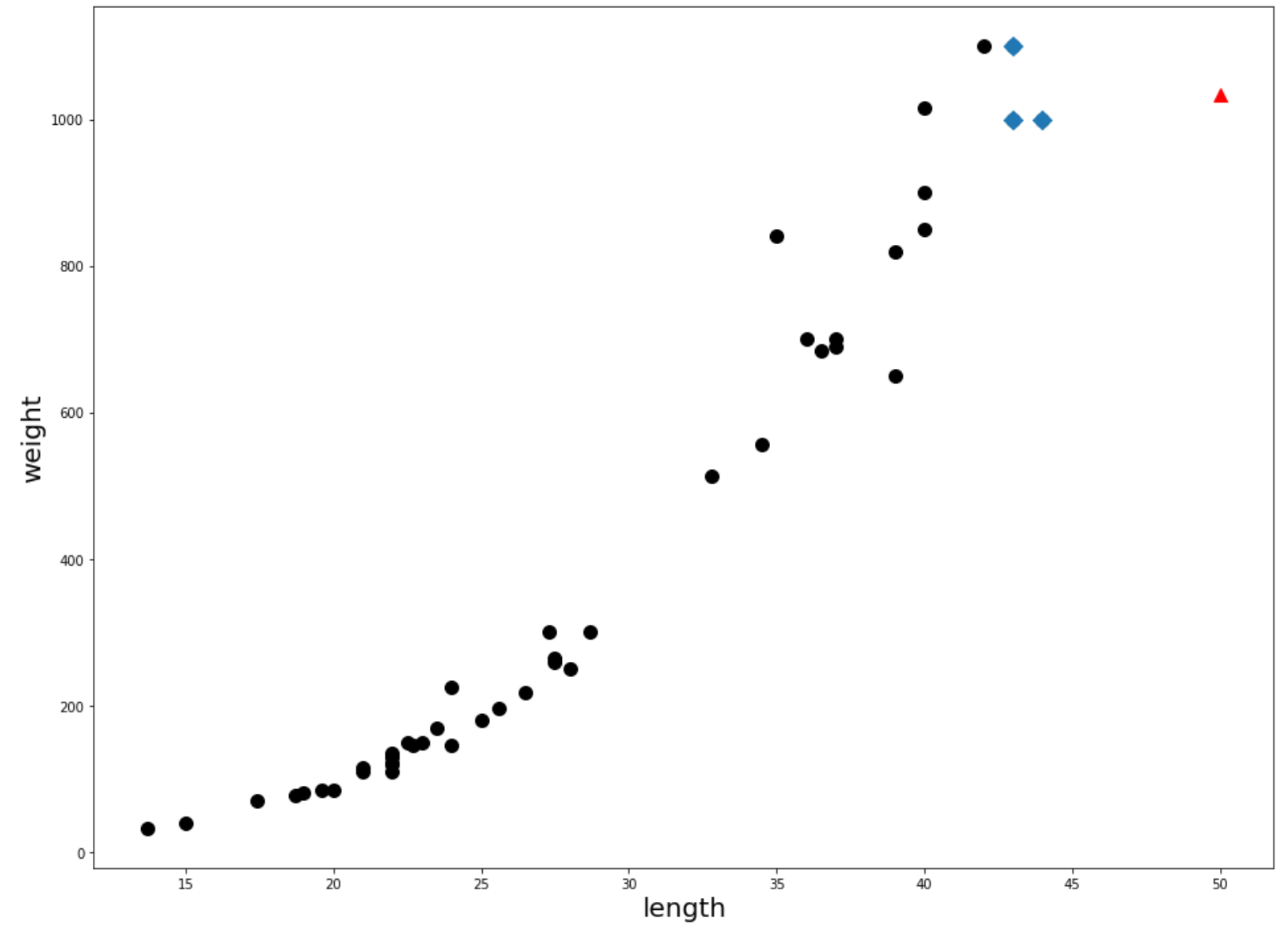
분명 이전까지는 무게가 길이에 비례하여 증가하였는데 새로운 데이터는 비례관계를 보이지 않습니다. 값이 커져도 근접한 이웃들의 평균값을 예측값으로 사용하기 때문입니다. K-최근접 이웃 모델에서는 학습된 데이터의 범위를 넘어서는 데이터가 새로 유입되면 모델이 정확한 값을 예측하지 못하게 됩니다.
참고서적
혼자 공부하는 머신러닝+딥러닝, 2020, 박해선
위키백과 - K-최근접 이웃 알고리즘
'DataScience' 카테고리의 다른 글
| [ML] 교차 검증(cross validate) (0) | 2022.08.22 |
|---|---|
| [ML] train_test_split을 이용한 데이터 분할 (0) | 2022.08.22 |
| [ML] SimpleImputer (누락값 처리) (0) | 2022.08.04 |
| [ML] 모델 파라미터와 모델 하이퍼 파라미터 차이 (Difference between a model parameter and a model hyper parameter) (0) | 2022.08.02 |
| [ML] K-NeighborsClassifier(K-최근접 이웃) (0) | 2022.07.30 |