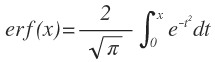[Numpy] ndarray
Numpy의 근간은 ndarray 객체이다. 리스트는 C의 배열과 다르게 각 요소들의 주소가 연속적이지 않다. 반면 Numpy의 ndarray는 각 요소들의 주소가 연속적이다. 이는 계산의 속도를 향상해 느린 연산 속도를 갖는 파이썬의 단점을 없애준다. 1. ndarray의 생성 1) array import numpy as np matA = [[1, 2, 3],[4, 5, 6], [7, 8, 9]] matB = np.array(matA) #리스트로 생성 matC = np.array(((1, 2, 3), (4, 5, 6), (7, 8, 9))) #튜플로 생성 print(type(matA)) print(type(matB)) print(type(matC)) 결과를 보면 알 수 있듯이 리스트와 튜플 모두 nda..