[Pandas] 함수 정리
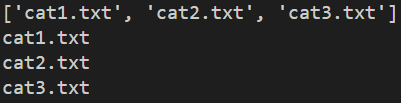
pandas 라이브러리에서 사용하는 함수 정리 1. 생성 import pandas as pd # Dict를 입력값으로 받는 경우 # Key는 column이 된다 df = pd.DataFrame({'a': [4, 5, 6, 7], 'b': [8, 9, 10, 11], 'c': [12, 13, 14, 15]}, index=[1, 2, 3, 4]) # List를 입력값으로 받는 경우 # 각 리스트는 row가 된다 df2 = pd.DataFrame( [[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], [13, 14, 15, 16]], index=[1, 2, 3, 4], columns=list('abc')) 2. 이중 인덱스 데이터프레임 # index를 MultiIndex로 설정 #..